
第四の化学、データ科学の最前線を行く
髙橋 啓介 教授 TAKAHASHI Keisuke/情報化学研究室

実験・理論・計算化学の先にデータ科学がある
航空機の設計やコンピュータの開発に興味があり、アメリカのアリゾナ大学に入学して航空機の設計を学び始めました。そこでは、飛行機をコンピュータと実験で設計する一方、極限の環境に耐えうる材料や特殊な機能を追求する材料科学に魅かれていきました。
大学院はスウェーデンのチャルマース工科大学の材料科学に進みましたが、理論化学と計算化学に興味を持ち、触媒科学の研究室で計算化学による研究を始めました。そこでは、自動車の触媒を研究していて、一酸化窒素を浄化する触媒を理論化学・計算化学から探すといった研究に従事しました。その後博士後期課程で北大に移り、実験と計算化学から水素貯蔵材料の研究を行いました。このように実験、理論、計算と3つの異なる化学を扱って材料設計してきた中で、化学では実験結果・知識・文献がデータとして存在していることに気が付きました。そこで人工知能に代表されるデータ科学を使い、データから材料や化学反応を設計する研究にシフトしていきました。そのような経緯で、NIMS(国立研究開発法人物質・材料研究機構)の研究員となり、2019年には北大の化学部門の理論化学研究室に准教授として着任しました。
化学を飛躍させる人工知能
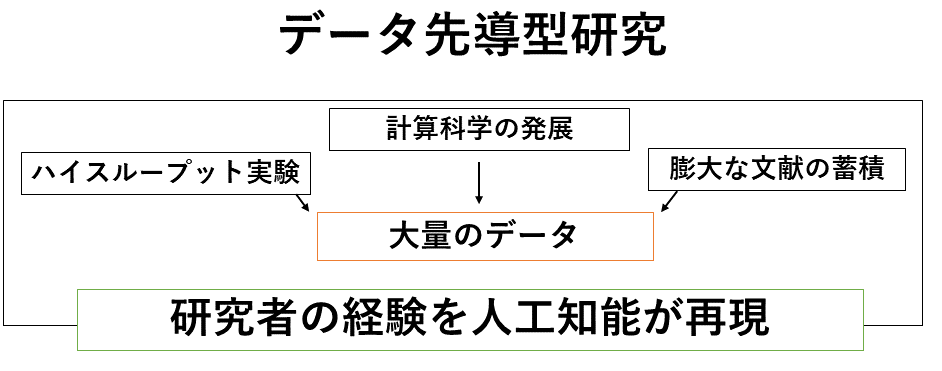
化学反応は材料の組み合わせ、材料の調製方法、分量、温度、圧力などが複雑に関係して生まれます。そのため新しい化学反応を見つけるのはどんなに経験値があったとしても膨大な探索空間の中から見つけなくてはならなく、膨大な数のトライ&エラーが必要でした。しかし、よく考えてみると世の中の自然現象はデータとして観察すると何らかの法則で成り立っていることがわかります。そこで実験データ、計算データ、世の中に存在している文献データから、データ科学の手法を使って材料や触媒を設計する研究を始めました。究極の目指すところはこれまでの研究者の経験やひらめきを人工知能が再現することです。これが達成されれば未知の材料・触媒の開発スピードが爆発的に加速するだけでなく、化学の概念も大きく変わるでしょう。
今はCRESTというプロジェクトの代表を務めており、データ科学を使いメタンをエチレン・エタンなどに直接変換する触媒・技術を開発しています。そこでは、自分たちで実験・計算データを作り、そこから人工知能を使って未知の触媒の予測と設計を行っています。特に触媒の探索は難しく、100度で結果が出ても200度ではうまく行かないなど状況に依存することが多く、生き物を扱っているみたいな感覚です。しかし、実際に人工知能を使うと、人間が考えもしない触媒が提案され実験で実証されるなど、化学データからの触媒設計が可能になりました。

よく「データ科学は実験・計算化学と何が違うのですか?」と聞かれることがあります。実験・計算化学では研究者が経験・勘をもとに実験のサンプルや計算のモデルを作成し評価します。この過程を繰り返すことにより新しい材料や触媒が発見されます。ところがデータ科学では、人工知能が化学データを学習します。この頭の良くなった人工知能に対して、研究者は「欲しい性質をもつ材料・触媒」を人工知能に問います。すると人工知能は「こんな材料や触媒の候補があります」と導いてくれます。私のCRESTでは人工知能に「メタンを効率よくエチレンに直接変換する触媒が欲しい」と問うと、人工知能は「この触媒をこの実験条件で」と、触媒だけでなく実験手順まで教えてくれます。このように熟練の研究者が経験で探っていた触媒の組み合わせや実験条件を人工知能で再現できれば、触媒設計が大きく変わります。
データをつくる実験装置も作る
人工知能は最初から賢いわけではないので、質の高い化学データを教え込む必要がありますが、一人の研究者が1日一つの結果を得るようなペースでは短期間で質の高い大量のデータを手に入れることは難しいです。そこで、「ハイスループット実験」装置を私のCRESTチームで開発し運用しています。「スループット」は聞きなれない言葉かもしれませんが、実験のサンプル作成から評価、解析までの一連の流れのことを指します。この一連の流れを例えば20個のサンプルを同時に作成し、同時に評価・解析するとスループット性が20倍になったと言います。このようにスループット性を上げることをハイスループットと言います。
私のチームで開発したハイスループット実験装置は1日に数千回の実験を可能にします。この結果、過去30年ほどで蓄積された2000点の実験データの6倍となる12,000点のデータを3日で取得できる実験装置になりました。この規模の触媒データを揃えられるのは世界で私のCRESTチームだけです。この大量の化学ビッグデータと人工知能を連携し触媒設計を進めています。さらに発展させて、触媒以外の材料科学全般、磁石、半導体や太陽電池などデータ科学を幅広く応用し材料・触媒開発しています。いま私の研究チームでは、「データ科学」を主力として、実験化学、計算化学、理論化学に次いで第四の化学として確立しようとしています。
データ科学の新しさと可能性
日本中探しても、材料科学・触媒科学分野でデータ科学を教えている大学は私の研究室含めて数研究室あるかないかだと思います。アメリカでは最近2、3校がデータ科学科をつくり始めたくらいで、まだまだ世界的にも教えられる人も場所も少ない新しい分野です。プログラミングを含めてデータ科学技術は研究室に入ってから勉強しても大丈夫ですが、大事なのは化学の基礎知識を持っていることだと感じます。化学実験が好きで入った化学科で、同じような実験を何度も何度もやっているうちに「これって効率的にできないのかな」ってモヤモヤして、別の方法を考えたくなったら、それでデータ科学をやる目的として十分です。データサイエンスや人工知能はハードルが高いと思って躊躇する学生もいますが、これから科学全般、金融や経済などさまざまな分野でデータサイエンスを使う時代が来ている中でデータ科学技術を学ぶことはこれからの社会を担う必要技術を得ることになります。私達のところでは、化学とデータ科学が融合した実践的な研究を通して、将来どんな道に進んでも応用できる力がつくことを目指しています。
化学系や材料系の大企業ではデータ科学部門をつくって開発を進めようとしていますが、人材不足でよく相談に来られます。今後データ科学技術を持った人材の育成が急務と考えています。ただ、教科書も無いし、カリキュラムも確立していないほど新しい分野なので、教育は手探りです。「未踏の分野を自分たちが楽しみながら創っていくんだ」くらいの気持ちで進んでくれたらいいですね。
Message
いま、日本を含め世界では「データサイエンティストを何万人育てよう増やそう」と動いていますが、プログラミングができればなれるわけではありません。化学の基本知識はもちろんのこと、目の前にあるデータに対して、どのようなデータ科学技術が必要なのかを判断し、データの中に眠っている法則性を可視化したり人工知能に学習させる力を養うことが必須だと思います。
私たちのところでは、化学、数学、物理の基礎能力とプログラミングの実践に加えて、サーバ設計やパソコンの組み立てなどのハードもゼロからパーツを買ってきて自分たちでつくるようにしています。データ科学をやっている私たちにとってサーバやパソコンはれっきとした実験器具なので、パソコンの構成を把握した上でデータ科学を扱うように心がけています。
